Dr. Kazuhiro Fukuyo
Professor, Yamaguchi University
Last updated: November 27, 2011
cmb.map <- function( zdata, # 塗り分けのための統計データ=長さ24のベクトル
t, # データを 5 区分するための 4つの値
color.no=9, # 塗りつぶしに,何色系統を使うか
unit ) # 単位として用いる文字列
{
x <- readShapePoly("C:\\rtemp\\cmb\\KHM_adm\\KHM_adm1.shp") # 州境データ
y <- readShapePoly("C:\\rtemp\\cmb\\KHM_wat\\KHM_water_areas_dcw.shp") # 水域データ
yy <- y[y$F_CODE_DES == "Inland Water",] # 内水域データ
# 大河川・湖のみ抽出
yy1 <- yy[yy$NAME == "MEKONG",]
yy2 <- yy[yy$NAME == "TONLE SAB",]
yy3 <- yy[yy$NAME == "BOENG TONLE SAB",]
yy4 <- yy[yy$NAME == "TONLE BASAK",]
colnam <- rep("white", length=24)
color.set <- matrix(c( # 色の系統 color.no
"gray100", "gray75", "gray50", "gray25", "gray0", # 灰色1 1
"#eeeeee", "#bbbbbb", "#999999", "#777777", "#555555", # 灰色2 2
"#ee0000", "#bb0000", "#990000", "#770000", "#550000", # 赤色系 3
"#eeffee", "#aaffaa", "#00ee00", "#00bb00", "#009900", # 緑色系 4
"#0000ee", "#0000bb", "#000099", "#000077", "#000055", # 青色系 5
"#ee00ee", "#bb00bb", "#990099", "#770077", "#550055", # 紫色系 6
"#00eeee", "#00bbbb", "#009999", "#007777", "#005555", # 水色系 7
"#eeee00", "#bbbb00", "#999900", "#777700", "#555500", # 黄色系 8
"lemonchiffon", "yellow", "orange", "red", "darkred" # heat color 9
), byrow=TRUE, ncol=5)
if (length(t) != 4) {
stop("t は,長さ4のベクトルでなければなりません")
}
if (!(color.no %in% 1:9)) {
stop("color.no は,1〜9 の整数でなければなりません")
}
for (ii in 1:24) {
if (zdata[ii] > t[4]) {
colnam[ii] <- color.set[color.no, 5]
}
else if (zdata[ii] > t[3]) {
colnam[ii] <- color.set[color.no, 4]
}
else if (zdata[ii] > t[2]) {
colnam[ii] <- color.set[color.no, 3]
}
else if (zdata[ii] > t[1]) {
colnam[ii] <- color.set[color.no, 2]
}
else {
colnam[ii] <- color.set[color.no, 1]
}
}
x$ID <- x$ID_1 - min(x$ID_1)+1 # 行政区分の番号を追加
x$colnam <- colnam # 統計データに応じた色を追加
plot(x, col=x$colnam) # 人口密度で色分け
plot(yy3, col="white", lwd=2, add = TRUE) # トンレサップ湖表示
# 以下は凡例の描画用
oo <- par("usr") # プロット範囲(経度・緯度)をooに保存
ox <- oo[1] # 経度の値の小さい方を原点x座標に
oy <- oo[3] # 緯度の値の小さい方を原点y座標に
oxl <- oo[2] - oo[1] #
oyl <- oo[4] - oo[3] #
par(new = T) # 現在の図に新たな図を重ね書きする
for (ii in 1:5) {
aa <- c(ox + oxl * 15 / 20, ox + oxl * 15 / 20,
ox + oxl * 16 / 20, ox + oxl * 16 / 20)
bb <- c(oy + oyl / 20 * ii, oy + oyl / 20 * (ii + 1),
oy + oyl / 20 * (ii + 1), oy + oyl / 20 * ii)
polygon(aa, bb, col=color.set[color.no, ii])
if (ii < 5) text(ox + oxl * 16.5 / 20, oy + oyl / 20 * (ii + 1), labels = t[ii], adj = 0)
else text(ox + oxl * 15 / 20, oy + oyl / 20 * (ii + 1.5), labels = unit, adj = 0)
}
}
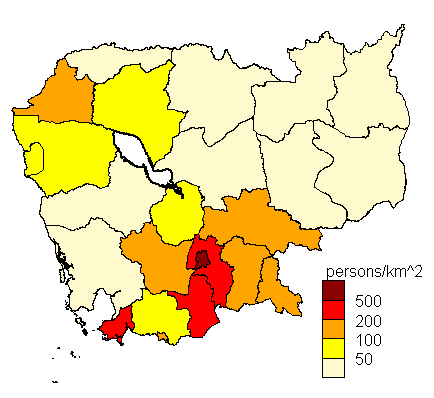
PD2008 <- c(102,88,172,85,102,46,74,355,13,106,29,88,230,4,30,4571,31,12,194,14,87,10,163,237)
t <- c(50, 100, 200, 500)
cmb.map(PD2008, t, 9, " persons/km^2 ")